
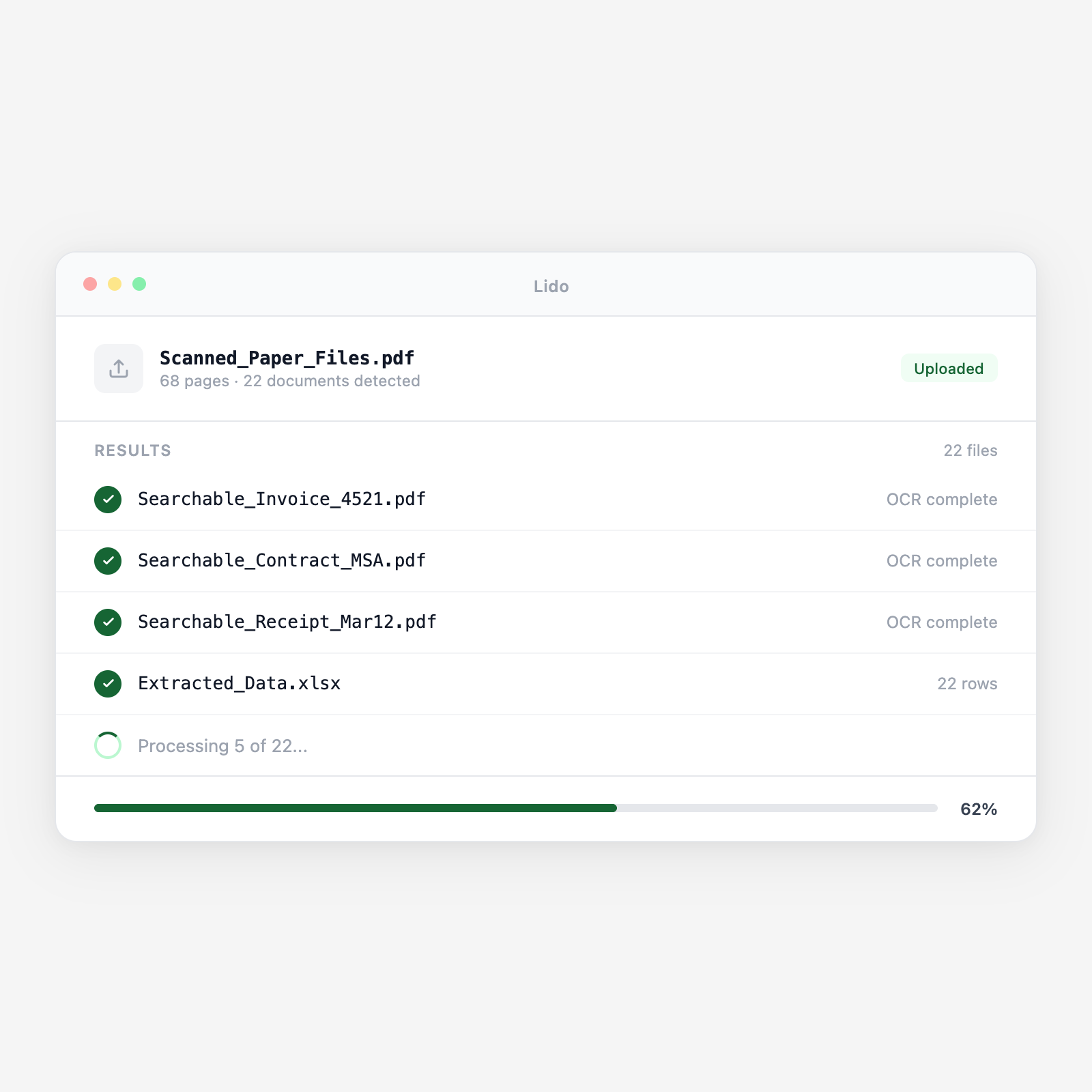
Scanned images, photos, and faxes become searchable PDFs with extracted structured data. Lido reads handwriting and handles any scan quality.
.png)
.png)

Drop TIFFs, JPEGs, or image-based PDFs into a watched folder or connect your scanner output. Lido picks up new files as they arrive.
Lido runs OCR on every page—handwritten, printed, or mixed—producing a searchable PDF with an embedded text layer.
Key fields are extracted into structured output—spreadsheet, database, or downstream system. Documents are named, organized, and delivered.
Upload a batch and get structured output in minutes.
| Feature | Lido | Basic scanner software |
|---|---|---|
| OCR with searchable text layer on every scan | ✓ | ✗ |
| Extract structured fields into a spreadsheet or database | ✓ | ✗ |
| Read handwriting and poor-quality faxes | ✓ | ✗ |
| Name and organize files based on extracted content | ✓ | ✗ |
| Process a backlog of historical scans in batch | ✓ | ✗ |
| Save scanned images as PDF files | ✗ | ✓ |
Make your entire document archive searchable and your key data extractable, in a single pipeline run.
Turn scanned intake forms, handwritten clinical notes, and faxed referrals into searchable PDFs with extracted demographics and insurance data.
Scan mail and fax invoices through Lido. Get searchable PDFs and extracted invoice data ready for ERP entry.
Digitize years of paper case files and court documents. Every page becomes searchable by case number, party name, or keyword.
Scan inspection checklists and compliance reports. Extract scores, dates, and site information for reporting and trending.
%20(1).svg)
