
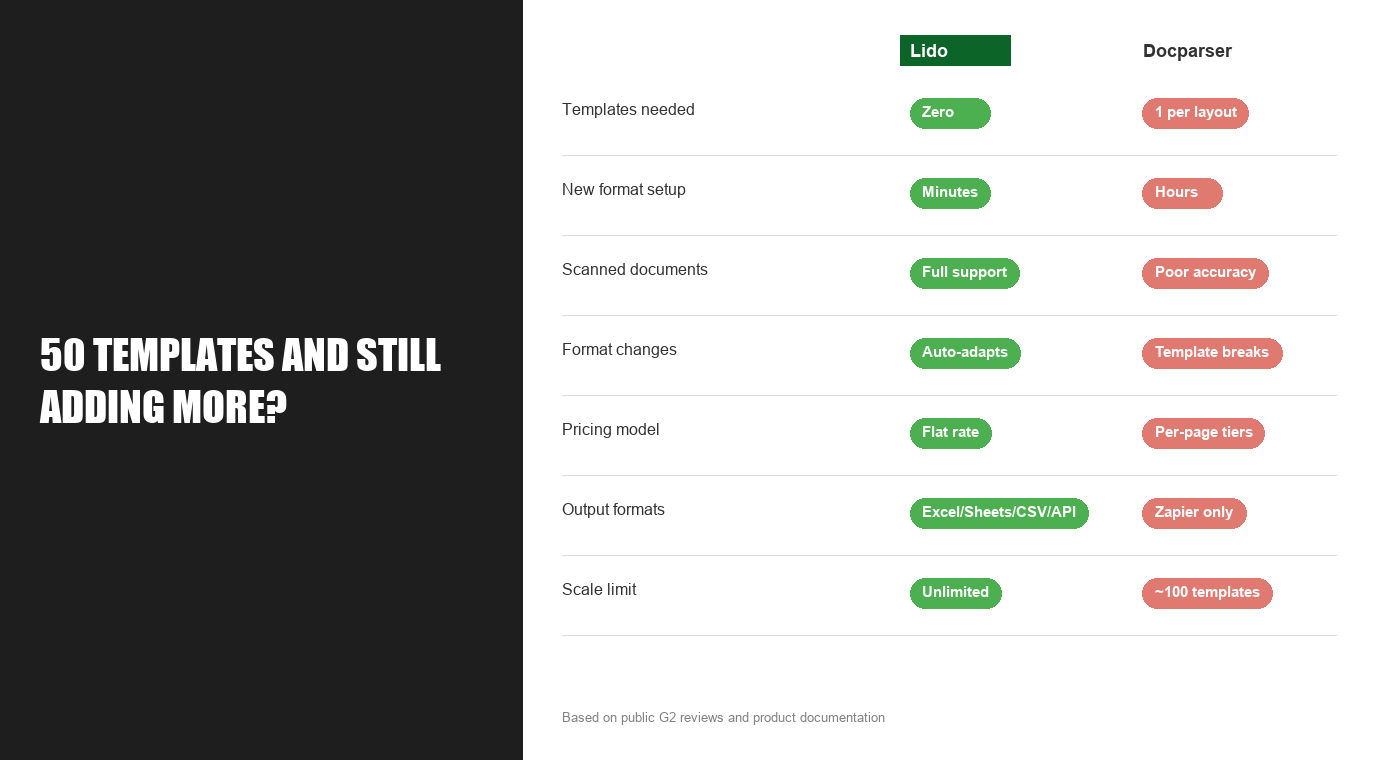
Lido is a template-free AI document extraction platform that processes any document format without requiring manual template creation or maintenance for each layout variation. Unlike Docparser, which needs a new template for every vendor format or layout change, Lido uses AI to extract structured data from invoices, receipts, POs, and other documents regardless of format. The platform outputs to Excel, Google Sheets, CSV, or API, eliminating the template management overhead that limits Docparser scalability.
Docparser does exactly what it promises for companies with a stable set of document formats. You set up a template, map your fields, connect a Zapier integration, and it runs. G2 reviewers call it "incredibly easy to use" for basic extraction, and its support team has earned genuine praise — "some of the most helpful folks I've worked with," one user wrote. For a company processing 5-10 document types that rarely change, it works.
The problem shows up when the number of formats grows. You add a new vendor and need a new template. A vendor updates their invoice layout and the existing template breaks. A client sends scanned documents and the parser returns garbage. You onboard a seasonal supplier with a layout you'll see twice a year and won't remember to template next time.
At around 50-100 templates, the tool that was supposed to eliminate manual work becomes manual work of its own. "Constant adjustments for complex documents can be frustrating," one G2 reviewer wrote. Another, reflecting on a longer experience, was blunter: "In 2022, this was our choice but now we feel it has become complacent and fallen behind alternatives."
If you're at that point — where template maintenance is eating more time than the extraction is saving — here's what to know about the alternatives and what actually changes when you switch.
Lido is the strongest Docparser alternative for teams that have outgrown template-based extraction. It uses AI to parse any document format without per-template setup—invoices, receipts, purchase orders, bank statements—regardless of layout or vendor. Companies that switched from Docparser to Lido stopped maintaining hundreds of templates and started processing new vendor formats on day one.
Docparser's architecture works by mapping zones on a document: this region contains the invoice number, this region contains the date, this table has the line items. When a document matches the template, extraction is fast and accurate. When it doesn't match, nothing happens — or worse, the wrong data gets pulled from the wrong fields.
This means every unique document layout needs its own template. And "unique" goes beyond different vendors. It's the same vendor with different formats for different entities. It's credit memos that look nothing like invoices. It's documents that arrive as scans where the zones shift because the paper was crooked on the scanner.
The math is straightforward. If you work with 200 vendors and each one has an average of 1.5 distinct document formats, you need 300 templates. Some of those will break when vendors update their layouts — which happens without warning. At that point, you need someone whose job is partially just maintaining templates.
There's also a hard ceiling on what Docparser can handle. The default page cap is 30 pages (50 max), and the file size limit is 20 MB. If you're processing multi-page audit workpapers, 50-page payroll reports, or large claims documents, you'll hit those limits regularly.
The most common migration path we see is Docparser to Nanonets. The reasoning makes sense: Nanonets promises AI-based extraction without rigid templates, so it should solve the scaling problem. And for straightforward use cases, it does.
But model-trained tools introduce their own version of the template problem. Instead of building templates per layout, you train models per document type. The initial training takes 2-4 weeks. When formats change or you add new vendors, you retrain. One company that made this exact migration — Esprigas, a gas distribution company processing 27,000 documents a month — described the experience:
"We moved from DocParser which was a template-based OCR provider... to Nanonets... we spend a ton of time retraining the models."
They'd left Docparser to escape template maintenance and ended up with model maintenance instead. Four calls into evaluating their next tool, they were still looking for something that doesn't require teaching the system every format it encounters.
This pattern — Docparser to Nanonets to still not satisfied — is common enough that it reveals something about the problem itself. The issue isn't which tool you use for template-based extraction. It's the template approach. Any tool that needs to learn a document format before it can read it will create maintenance work proportional to the number of formats you process.
The right replacement depends on what's actually broken in your workflow. If Docparser works fine but you need more integrations or higher page limits, a similar tool with better specs might be enough. If the fundamental problem is template maintenance at scale, you need a different architecture.
Layout-agnostic extraction. The tool should process a document it has never seen before — new vendor, new format, new layout — on the first upload, without any setup. If someone has to configure something before the tool can read a new document type, you're buying the same problem again.
Scanned document handling. Docparser struggles with scanned documents because zone-based mapping depends on precise positioning. Scanned documents are never precisely positioned. Your alternative needs to handle scans, faxes, and low-quality copies natively.
No page or file size limits that matter. If you're outgrowing Docparser partly because of the 30-page cap and 20 MB file limit, make sure the replacement doesn't have similar constraints.
Reprocessing without penalty. When extraction isn't perfect on the first pass, you need to be able to adjust and re-run. Tools that charge per attempt create an incentive to accept imperfect results rather than fix them.
These Docparser alternatives use AI-based extraction instead of rigid templates, which means they can handle new document layouts without manual rule creation. Here is how they compare.
Best for: Operations teams processing documents from 100+ vendors with unpredictable layouts, scanned inputs, and handwritten fields — without building or maintaining templates.
Lido uses a custom blend of AI vision models, OCR, and LLMs instead of templates or model training. You upload a document, describe what you want extracted in plain English, and get structured data back. It works on any layout, any quality, and any document type without prior configuration.
For teams leaving Docparser specifically, the key differences are: no setup per document format, no rules to maintain when layouts change, native handling of scanned and handwritten documents, support for documents over 500 pages, and 24-hour free reprocessing on every extraction. A CPA firm processing 3,500 audits a year across thousands of payroll formats uses a single Lido setup. A trucking company processing 360,000 pages a year replaced 6 data entry employees with automated extraction of handwritten driver tickets.
Where it's limited: Lido has fewer native out-of-the-box integrations than Docparser's Zapier triggers. You can connect via API, but if you need pre-built connectors to specific downstream systems on day one, check whether yours are supported.
Best for: Teams processing 3-5 recurring document types at moderate volume (under 5,000 documents/month) who have 2-4 weeks for initial model training and technical staff to manage retraining.
Nanonets uses machine learning models trained on your documents. Once trained, models can handle variations within a document type better than rigid templates. The platform includes workflow automation features and integrations with Salesforce, QuickBooks, and other business systems.
The tradeoffs are real but worth understanding clearly. Model training takes 2-4 weeks for the initial setup, and retraining is required when vendors change formats or you add new document types. G2 reviewers note that "training models for unique document types can be time-consuming." There's no free reprocessing — you're charged for every extraction attempt. Pricing is enterprise-focused and not published for smaller teams. If template maintenance is your core complaint about Docparser, model maintenance may feel similar — Esprigas made this exact migration and ended up evaluating a third tool.
Best for: Enterprises with 10,000+ documents/month, dedicated IT staff, and on-premises deployment or regulatory compliance requirements (HIPAA, SOX, GDPR).
ABBYY offers 150+ pre-trained models in a marketplace, covering common document types out of the box. It has strong enterprise compliance features and integrates with RPA platforms like UiPath and Blue Prism. It's the most established player in the intelligent document processing space.
The tradeoffs: Requires technical knowledge to configure and deploy — this is not a tool you set up in an afternoon. G2 reviewers cite the interface as unintuitive and note that "handwritten recognition could be improved." Support response times can be slow. For mid-market teams with fewer than 5,000 documents/month replacing Docparser, ABBYY is often more infrastructure than the problem requires.
Best for: Financial services teams processing invoices and bank statements from 10-50 vendors at volumes under 2,000 pages/month, especially teams wanting transparent per-page pricing.
Docsumo offers pre-built models for financial documents and a clean interface. Pricing is more transparent than most competitors — free up to 100 pages, then roughly $0.30 per page. That makes it easy to test and predictable to budget.
The tradeoffs: Accuracy weakens on complex layouts and high format variety. One reviewer noted that "because of the vast amount of variety in our invoices, Docsumo's systems can get mixed up occasionally." At $0.30 per page, costs add up at higher volumes — 10,000 pages/month would run $3,000. If you're leaving Docparser because of format variance across 100+ vendors, Docsumo may not handle that variability better.
Best for: Engineering teams with Google Cloud experience building custom extraction pipelines where they need full control over model selection, processing logic, and data flow.
Google Document AI provides pre-trained and custom-trainable models through Google Cloud. If your team has developers comfortable with cloud APIs and you want complete control over the extraction pipeline, it's a powerful option with Google-scale infrastructure behind it.
The tradeoffs: This is a developer tool, not a business tool. There's no interface for non-technical staff to upload documents or review extractions. You build, deploy, and maintain the extraction pipeline yourself. For teams that found Docparser's template setup too time-consuming, building and maintaining a custom cloud pipeline requires dedicated engineering resources — typically 2-4 weeks for initial build plus ongoing maintenance.
Best for: Teams parsing fewer than 500 emails or simple PDFs per month with Zapier-first workflows who don't need to handle format variability.
Parseur is similar to Docparser in approach — template-based parsing with strong integration hooks. It's particularly focused on email parsing and has tight Zapier and Make integrations. If your primary use case is pulling data from standardized emails or simple documents, it handles that well.
The tradeoffs: Same template-based architecture as Docparser, so the same scaling limitations apply at the same thresholds. If you're processing documents from 50+ vendors with format variability, Parseur won't change that equation. If you're leaving Docparser for better email parsing or slightly different integrations within the same approach, it might work.
Comparing specific competitors? See our detailed comparisons: Nanonets alternative, Parseur alternative, and ABBYY alternative for manufacturing.
If your Docparser templates work but you need better specs — higher page limits, more integrations, or faster processing — tools like Parseur or Docsumo offer incremental improvements within a similar paradigm.
If the problem is the template paradigm itself — 200+ vendors, 300+ templates to maintain, documents that don't fit any template — the alternative needs to work differently at the architecture level. Template-free, layout-agnostic extraction that handles any document on the first upload without configuration is what solves the scaling problem that brought you here.
Test whichever tool you evaluate with the documents that break your current templates. Not the clean, consistent ones that Docparser already handles well. The messy, inconsistent, scanned ones that made you start looking for an alternative in the first place.
Lido is the best Docparser alternative for teams processing documents from 100+ vendors with unpredictable layouts. Unlike Docparser's template-based approach, Lido extracts data from any document format without templates or per-vendor configuration — including scanned, handwritten, and dot matrix documents. Esprigas migrated from Docparser to Nanonets to Lido after finding that both template and model-trained tools required unsustainable maintenance across 27,000 documents monthly.
Lido is the leading layout-agnostic extraction tool — it processes documents it has never seen before on the first upload, with no templates to build and no models to train. You describe what to extract in plain language and get structured data back. A CPA firm uses a single Lido setup to process 3,500 compliance audits annually across thousands of different payroll document formats, with no per-format configuration.
Lido handles scanned, faxed, and handwritten documents with the same accuracy as born-digital PDFs — the exact documents that break Docparser's zone-based template mapping. Disney Trucking processes 360,000 handwritten driver tickets annually through Lido, and Kei Concepts extracts data from handwritten Vietnamese invoices across 13 restaurant locations. No special configuration or separate workflows are needed for degraded documents.
Lido requires no migration of templates or training data — you start extracting immediately by describing what you need in plain language. Esprigas, a gas distribution company processing 27,000 documents monthly from hundreds of vendors, went from Docparser to Nanonets to Lido after finding that both template and model-based tools required constant maintenance. With Lido, they process all vendor formats with a single configuration and reprocess free for 24 hours when extraction needs refinement.
%20(1).svg)
